|
| Recent Posts | - May, 2025-5,(1)
- April, 2025-4,(1)
- January, 2025-1,(1)
- July, 2024-7,(1)
- May, 2024-5,(2)
- May, 2023-5,(1)
- February, 2023-2,(1)
- November, 2022-11,(1)
- July, 2022-7,(2)
- March, 2022-3,(1)
- November, 2021-11,(2)
- August, 2021-8,(2)
- July, 2021-7,(2)
- June, 2021-6,(1)
- May, 2021-5,(1)
- March, 2021-3,(1)
- February, 2021-2,(2)
- January, 2021-1,(7)
- December, 2020-12,(3)
- March, 2020-3,(2)
- February, 2020-2,(1)
- December, 2019-12,(2)
- November, 2019-11,(1)
- October, 2019-10,(1)
- September, 2019-9,(1)
- August, 2019-8,(1)
- May, 2019-5,(1)
- April, 2019-4,(2)
- March, 2019-3,(2)
- December, 2018-12,(1)
- November, 2018-11,(4)
- July, 2018-7,(1)
- May, 2018-5,(3)
- April, 2018-4,(2)
- February, 2018-2,(3)
- January, 2018-1,(3)
- November, 2017-11,(2)
- August, 2017-8,(1)
- June, 2017-6,(3)
- May, 2017-5,(5)
- February, 2017-2,(1)
- December, 2016-12,(1)
- October, 2016-10,(2)
- September, 2016-9,(1)
- August, 2016-8,(1)
- July, 2016-7,(1)
- March, 2016-3,(2)
- February, 2016-2,(3)
- December, 2015-12,(5)
- November, 2015-11,(5)
- September, 2015-9,(1)
- August, 2015-8,(2)
- July, 2015-7,(1)
- March, 2015-3,(2)
- February, 2015-2,(1)
- December, 2014-12,(4)
- July, 2014-7,(2)
- June, 2014-6,(2)
- May, 2014-5,(3)
- April, 2014-4,(3)
- March, 2014-3,(1)
- December, 2013-12,(2)
- November, 2013-11,(1)
- July, 2013-7,(1)
- June, 2013-6,(2)
- May, 2013-5,(1)
- March, 2013-3,(3)
- February, 2013-2,(3)
- January, 2013-1,(1)
- December, 2012-12,(3)
- November, 2012-11,(1)
- October, 2012-10,(1)
- September, 2012-9,(1)
- August, 2012-8,(1)
- July, 2012-7,(6)
- June, 2012-6,(1)
- April, 2012-4,(1)
- March, 2012-3,(3)
- February, 2012-2,(3)
- January, 2012-1,(4)
- December, 2011-12,(3)
- October, 2011-10,(3)
- September, 2011-9,(1)
- August, 2011-8,(10)
- July, 2011-7,(2)
- June, 2011-6,(7)
- March, 2011-3,(2)
- February, 2011-2,(3)
- January, 2011-1,(1)
- September, 2010-9,(1)
- August, 2010-8,(2)
- June, 2010-6,(1)
- May, 2010-5,(1)
- April, 2010-4,(3)
- March, 2010-3,(2)
- February, 2010-2,(3)
- January, 2010-1,(1)
- December, 2009-12,(3)
- November, 2009-11,(3)
- October, 2009-10,(2)
- September, 2009-9,(5)
- August, 2009-8,(3)
- July, 2009-7,(9)
- June, 2009-6,(2)
- May, 2009-5,(2)
- April, 2009-4,(9)
- March, 2009-3,(6)
- February, 2009-2,(4)
- January, 2009-1,(10)
- December, 2008-12,(5)
- November, 2008-11,(5)
- October, 2008-10,(13)
- September, 2008-9,(10)
- August, 2008-8,(7)
- July, 2008-7,(8)
- June, 2008-6,(12)
- May, 2008-5,(14)
- April, 2008-4,(12)
- March, 2008-3,(17)
- February, 2008-2,(10)
- January, 2008-1,(16)
- December, 2007-12,(6)
- November, 2007-11,(4)
|
|
|
|
|
SQL Instance will not fail back to primary
|
9/15/2008 11:06:17 AM
|
|
|
Better known as, "Polyserve is puking and you get to clean it up !". Technincally it's not fair to blame Polyserve, as the root cause of this issue looks to be a corrupt registry from version 3.4 that was never properly corrected. We've never experienced an issue like this with SQL Instances installed from version 3.6 originally.
When you have a SQL Server instance in Polyserve that will not fail back to it's primary, you know you have a problem. Best bet, call technincal support [that's what maintenance is for!], but here is what happenned to us recently and what we did to correct this issue [we have seen this before and called technical support and concurred this is the permanent fix].
Automated patching of the development environment caused some sql instances to fail over, this is expected. We do not run the instances in "auto fail back" mode, preferring to complete this step manually to minimize "ping-ponging" instances. After patching we reviewed the environment, and it looks good, with the excpetion of one instance, it is on it's secondary, it is running, it is available, but notice the status of "warning".

There is no nice error message in the console. Right clicking the instance to "show alerts", displays nothing. What gives ?
Who cares right, just move the instance back to the primary and let's get working....no dice. The instance won't move, and NO Error or Message is given, crap, you know your in trouble now....for the newly Polyserve initiated, this is when you STOP and call technical support. The more you play with things, the worse it will get and it will cause technincal support consternation in correcting the issue. Since this was development I get to play...
The instance will not fail back, if we rehost, that result is no change. Disabling the instance is the same result. I'm pretty sure you could reboot the server and that would cause it to fail back to the primary, matter of fact, i'm positive....but what if you have other instances on that same physical server and you can't afford an outage ? Also that may temporarily correct the issue, but it doesn't address the root cause and future scenarios of patching or fail over, may result in the same condition.
What the hell is happenning ?
Finally digging through all the logs (including Polyserve logs), i find that Polyserve still thinks the instance is "starting", and since it is in "starting mode", it does not fail it over when requested. There needs to be someway of over-riding this stupid behavior but it is "by design". See pic:

What and why ? Based on past experience and knowing this instance existed from version 3.4 to 3.6, I know this deals with the registry issues. A quick peak of the registry on the server it is currently hosted on shows that some of the registry entries point to the virtual root (3.6) and some of the registry entries point to mxshells (3.4), notice the registry entries below, they should all point to the virtual root:

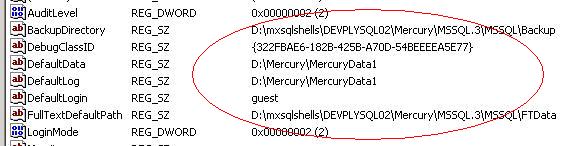
Now the correct way to fix this is to delete the sql instance from Polyserve (not the machines). Verify the registry entries and sql instance on each machine. Delete any polyserve sql.original, sql.preg etc files (make a copy first). Re-virtualize it and re-verify everything.
Obviously if this is production instance, you might have to wait in doing this, as it is time consuming. In which case you can manually stop the services and see if you can get things to fail back, though you may have to reboot the server. At some point, the only way to correct the root cause is find a maintenance window to allow you to delete the instance from polyserve, correct each individual sql instance and re-virtualize. Fun !
|
Blog Home
|
|